Training Models Across Multiple Machines - The Federated Learning Way
Federated Learning (FL) has emerged as a groundbreaking approach to training machine learning models, especially when data privacy is a top priority. Imagine harnessing the collective learning power of thousands of devices—all without ever pooling their data in a central location. That’s the promise of FL. At its core, a central server—known as the leader—orchestrates training across multiple distributed clients or learners.
In this detailed exploration, we’ll dive into the intricacies of building a federated learning system from scratch. Our toolkit includes a custom ResNet model, gRPC for communication, and Python. Through this journey, you’ll see how these components come together to create a robust federated learning system.
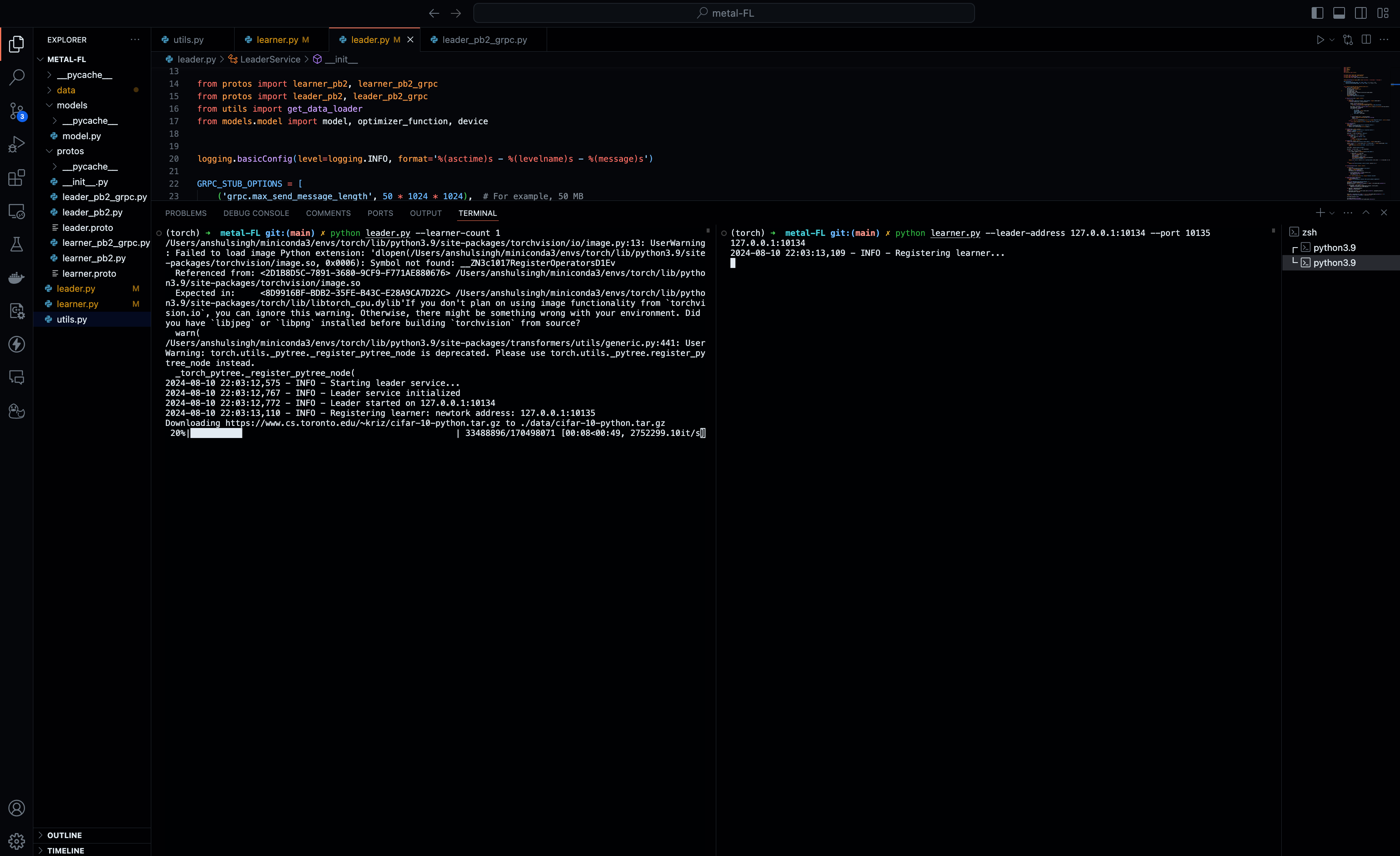
The Architecture: A High-Level Overview
Federated learning’s architecture is both elegantly simple and incredibly powerful. It revolves around two primary components:
- Leader (Server): The central authority that manages the global model, aggregates updates from learners, and disseminates the refined model.
- Learners (Clients): These are the distributed devices that train on local datasets and send model updates (gradients) back to the leader.
The workflow begins with learner registration, where each learner connects to the leader, registers itself, and receives its portion of the data for training. Next comes model synchronization, where learners fetch the latest global model from the leader. Then, local training takes place—learners train on their local data, compute gradients, and send them back to the leader. Finally, the global model is updated as the leader aggregates these gradients, refining the model. This cycle repeats until the model converges to the desired level of performance.
This architecture is the heart of federated learning, allowing data to remain decentralized, which significantly enhances privacy while still enabling robust model training.
The Leader Service (leader.py)
The leader service is the command center of the federated learning setup. Its primary responsibilities include initializing the global model and optimizer, managing learner registration by assigning unique IDs and datasets, and aggregating gradients from learners to update the global model. Communication between the leader and the learners is handled by gRPC, making the process efficient and scalable. gRPC supports complex data serialization through Protocol Buffers, which ensures that even large models and datasets can be handled effectively.
The Learner Service (learner.py)
On the client side, the learners take on the responsibility of training the model. They begin by synchronizing their local models with the global model maintained by the leader. Local training is then conducted on their respective datasets. After training, learners compute the necessary gradients and send these back to the leader for aggregation. The learner’s role is critical, as it ensures that the global model is continuously refined using diverse data from multiple sources—all while the data itself remains decentralized.
gRPC and Protocol Buffers: The Backbone of Communication
gRPC, combined with Protocol Buffers, forms the backbone of communication in this federated learning system. gRPC is a high-performance, open-source framework that allows for efficient, scalable communication between the leader and learners. It is particularly well-suited for this task due to its support for streaming and its ability to handle complex data serialization.
Protocol Buffers (.proto files) define the structure of the messages and services used in this communication. They act as a contract between the leader and learners, ensuring consistency and efficiency throughout the federated learning process.
Diving into leader.proto
The leader.proto file is essential to the gRPC communication in our federated learning system. It defines the services that the leader provides to the learners and the structure of the messages exchanged.
Here’s a breakdown of the key components:
syntax = "proto3";
package leader;
service LeaderService {
rpc RegisterLearner(LearnerInfo) returns (AckWithMetadata) {};
rpc GetModel(Empty) returns (stream ModelChunk) {};
rpc GetData(LearnerDataRequest) returns (stream DataChunk) {};
rpc AccumulateGradients(GradientData) returns (Ack) {};
}
The RegisterLearner service registers a new learner with the leader, assigning a unique ID and confirming successful registration. The GetModel service sends the current global model to the learner in chunks, ensuring that the learner is always working with the latest version of the model. The GetData service sends the relevant dataset to the learner, again in manageable chunks. Finally, the AccumulateGradients service receives the gradients computed by the learner after local training, allowing the leader to update the global model.
Services Explained:
RegisterLearner:- Purpose: Registers a new learner with the leader.
- Input:
LearnerInfo(contains the learner’s network address). - Output:
AckWithMetadata(acknowledges registration, provides learner ID and metadata). - Use Case: When a learner joins the network, it sends its network address to the leader, which then assigns it an ID and confirms successful registration.
GetModel:- Purpose: Sends the current global model to the learner in chunks.
- Input:
Empty(no additional input needed). - Output: Stream of
ModelChunkmessages. - Use Case: Learners request the latest version of the global model before starting or continuing their local training.
GetData:- Purpose: Sends the relevant dataset to the learner.
- Input:
LearnerDataRequest(contains the learner’s network address). - Output: Stream of
DataChunkmessages. - Use Case: When a learner needs data for local training, the leader provides it in manageable chunks.
AccumulateGradients:- Purpose: Receives the gradients computed by the learner after local training.
- Input:
GradientData(contains the gradient information). - Output:
Ack(acknowledges receipt of gradients). - Use Case: After completing local training, the learner sends its gradients to the leader, which aggregates them to update the global model.
message LearnerInfo {
string network_addr = 1;
}
message LearnerDataRequest {
string network_addr = 1;
}
message AckWithMetadata {
bool success = 1;
string message = 2;
int32 learner_id = 3;
int32 max_learners = 4;
}
message Ack {
bool success = 1;
string message = 2;
}
message Empty {}
message ModelChunk {
bytes chunk = 1;
}
message DataChunk {
bytes chunk = 1;
}
message GradientData {
bytes chunk = 1;
}
Message Types Explained:
LearnerInfoandLearnerDataRequest: These messages contain the network address of the learner, ensuring the leader knows where to send the model or data.AckWithMetadataandAck: These messages are used to acknowledge successful operations, such as registering a learner or receiving gradients.AckWithMetadataalso includes additional details like the learner’s ID and the total number of learners.ModelChunk,DataChunk, andGradientData: These messages are used to send portions of the model, dataset, or gradients, respectively. The use ofbytesallows for flexible handling of potentially large data chunks.
Why leader.proto is Critical
The leader.proto file serves as the contract between the leader and the learners. It defines how the leader will interact with the learners, specifying exactly what information is exchanged and in what format. This ensures that the distributed training process runs smoothly, with each learner and the leader understanding their roles and the data they need to share.
By using gRPC with this proto file, we achieve a scalable and efficient communication system that is essential for coordinating complex tasks like federated learning. The design ensures that the leader can manage multiple learners simultaneously, distribute models and data effectively, and aggregate learning updates to continuously improve the global model.
Deep Dive into learner.proto
Similarly, the learner.proto file is critical in defining how learners interact with the leader. It outlines the services that learners use to receive the global model, synchronize it, and participate in the training process.
Here’s the structure:
syntax = "proto3";
package learner;
service LearnerService {
rpc StartTraining(Empty) returns (Ack) {};
rpc SyncModelState(ModelState) returns (Ack) {};
}
message ModelState {
bytes chunk = 1;
}
message Empty {}
message Ack {
bool success = 1;
string message = 2;
}
The StartTraining service initiates the training process on the learner’s device, while the SyncModelState service ensures that the learner’s local model is always synchronized with the global model from the leader. These services and message types form the foundation of the learner’s ability to participate in the federated learning process.
The Model Architecture (model.py)
The model.py file houses the ResNet model—a powerful deep learning architecture well-suited for image classification tasks. The ResNet model leverages residual connections to mitigate the vanishing gradient problem, allowing for the construction of deeper networks. Training is conducted using Stochastic Gradient Descent (SGD) with Cross-Entropy Loss, both of which are standard for classification tasks. This architecture provides the learners with a robust model that can generalize well across various datasets.
Utility Functions (utils.py)
The utils.py file plays a crucial role in managing data. It handles data loading and preprocessing for datasets like CIFAR-10, ensuring that each learner gets a unique subset of data. Additionally, it applies data augmentation techniques, such as normalization and resizing, which are essential for improving the model’s generalization capabilities.
The Federated Learning Workflow: A Step-by-Step Guide
Let’s walk through the entire federated learning workflow. It begins with learner registration, where each learner connects to the leader and receives a unique ID and a portion of the dataset. Learners then fetch the latest global model from the leader through model synchronization. Next, each learner trains on its local data, computing gradients based on the model’s performance. These gradients are sent back to the leader, which aggregates them to update the global model. This process repeats until the global model converges, meaning it reaches the desired level of performance.
This workflow allows the system to learn from distributed data sources without centralizing sensitive data, making it both scalable and secure.
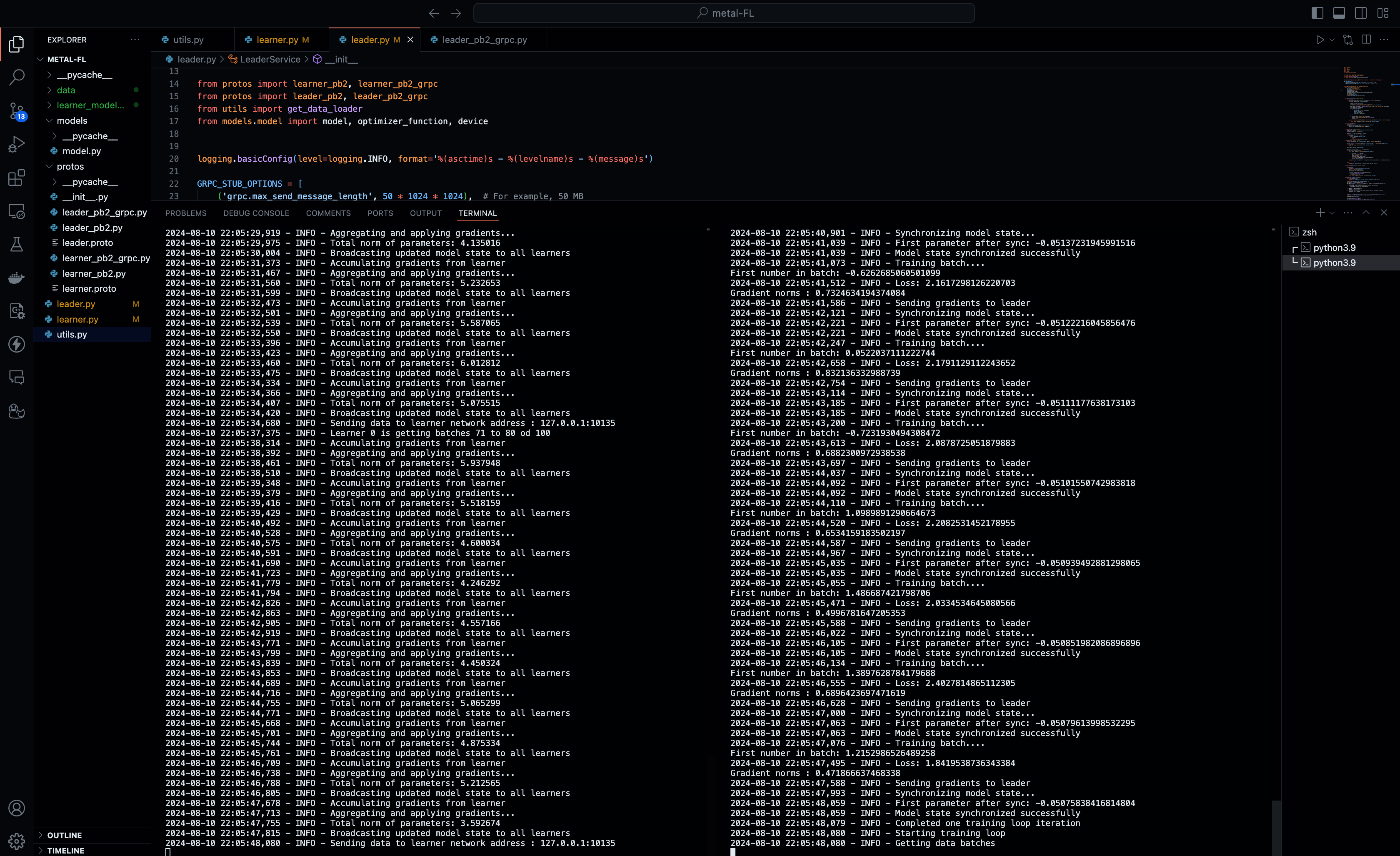
Federated Learning vs. Distributed Training: Understanding the Differences
Federated learning and distributed training may seem similar—they both involve training models across multiple devices or nodes. However, the key differences lie in data locality and privacy.
In distributed training, data is often pooled together from multiple sources and then split across multiple machines to parallelize the training process. The focus here is on speeding up the training process by leveraging the computational power of multiple nodes, but the data is centralized before training begins.
Federated learning, on the other hand, keeps the data decentralized. Training happens locally on each learner’s device, and only the model updates (gradients) are shared with the central server (leader). This approach is inherently more privacy-preserving because the raw data never leaves the learner’s device.
Conclusion
Federated learning represents a significant shift in how we approach machine learning. By decentralizing the training process and keeping data local, we can build robust models that respect privacy and security concerns. This blog has walked you through the architecture, the critical role of gRPC and Protocol Buffers, and the detailed workings of the leader.proto and learner.proto files. With this foundation, you’re now equipped to explore and implement federated learning in your projects.