Eveything Everywhere at once - A Distributed Training Saga...
Training large models on vast datasets used to be a test of patience for me. Hours would pass as I kept an eye on my machine, ensuring it didn’t idle out, all while feeling the frustration mount. It was evident that if I could harness the power of multiple GPUs simultaneously, training would be significantly faster. So, I decided to go deep into Distributed Training.
Initially, I was skeptical. I thought mastering it required an in-depth understanding of GPU internals and computer networking. However, it turns out, you can get by just fine without diving into those complexities. But before we dive deeper, let’s address the fundamental question: Why Distributed Training?
Firstly, it saves time. This much is obvious. Secondly, it increases the amount of compute power we can throw at the problem, ultimately helping us train our models faster. As models grow larger, it becomes increasingly difficult to put them to a single GPU and train. So this is where distributed data parallel comes in, but
What does Distributed Data Parallel (DDP) do exactly?
In traditional single-GPU training, the model resides on one GPU, receiving input batches from a data loader. It performs a forward pass to calculate the loss, then a backward pass to compute parameter gradients. These gradients are then used by the optimizer to update the model. But what if we distributed this process across multiple GPUs? With DDP, one process is launched per GPU. Each process holds a local copy of the model and optimizer. These replicas are kept identical, with DDP ensuring synchronization throughout the training process.
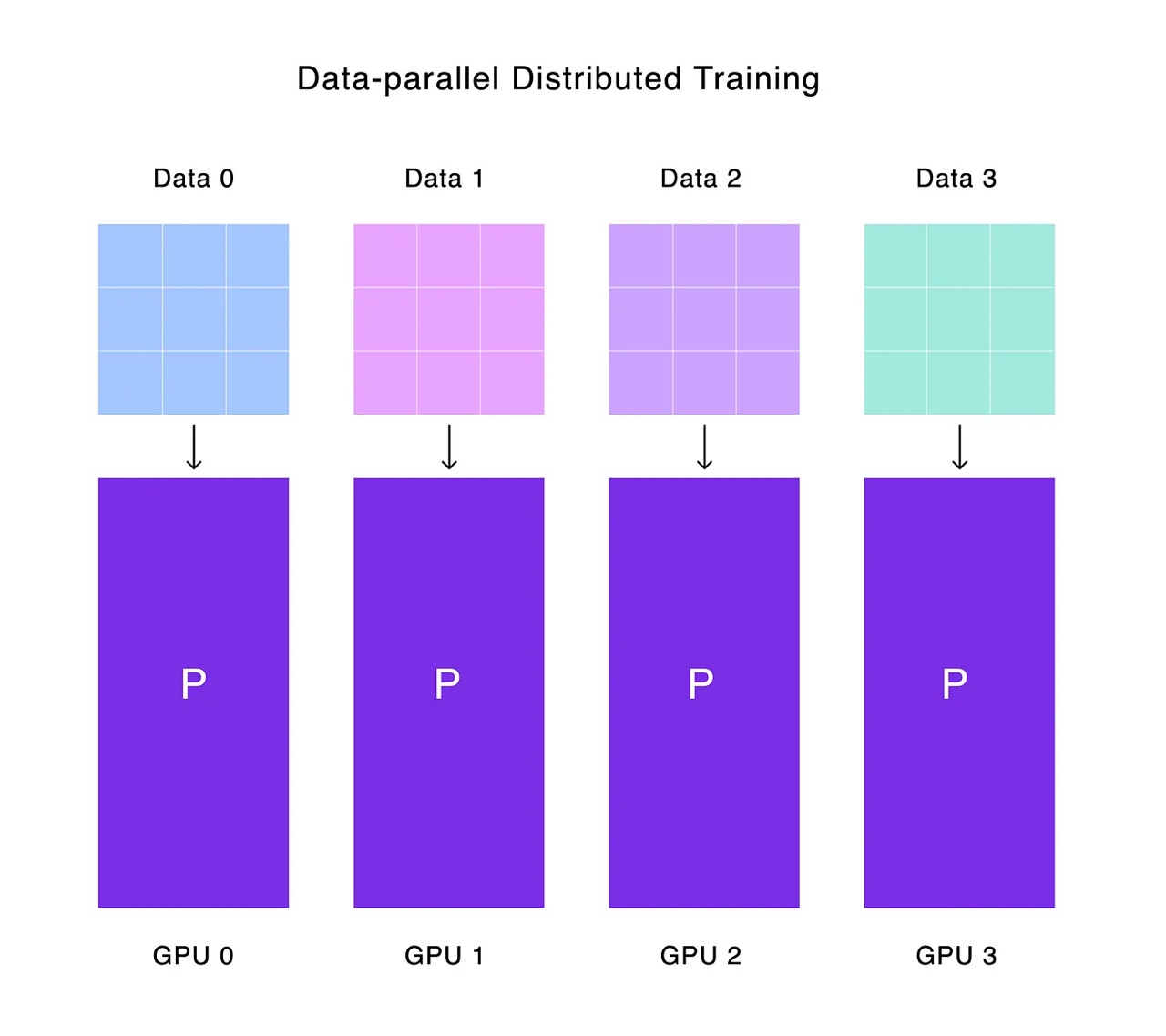
Each GPU process works on different data, but how do we ensure this? Enter the distributed sampler, paired with the data loader. It ensures that each GPU process receives different inputs—a technique known as data parallelism. This allows us to train multiple data instances concurrently with the same batch size. But With each process model recieves different input, loacally run forward and backward pass and beacuse the inputs were different then the gradient accumulated now are also different. Running the optimizer at this stage would yield distinct parameters across devices, resulting in separate models. DDP circumvents this issue by initiating a synchronization step. Gradients from all replicas are aggregated using a bucketed ring all-reduce algorithm. This process overlaps gradient computation with communication, ensuring GPUs are never idle. The synchronization step doesn’t wait for all gradients to be computed. Instead, it starts communication along the ring while the backward pass is ongoing. This keeps the GPUs busy and optimizes efficiency. Now each model replica has the same gradients,and now running the optimizer step now will update all the replicas parameters to same value. After each training epoch, all replica models remain in sync, thanks to this coordinated effort.
Implementing DDP (Distributed Data Parallel) is quite straightforward. It involves making minor adjustments to your code while keeping the overall structure intact. Whether you’re working on a single machine with multiple GPUs or across multiple nodes, the process is similar. Let’s delve into the code for training on a single GPU and then transition to multi-GPU via DDP.
Single GPU Training Code:
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self, size):
self.size = size
self.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]
def __len__(self):
return self.size
def __getitem__(self, index):
return self.data[index]
class Trainer:
def __init__(self, model, train_data, optimizer, gpu_id, save_every):
self.gpu_id = gpu_id
self.model = model.to(self.gpu_id)
self.train_data = train_data
self.optimizer = optimizer
self.save_every = save_every
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
def _run_epoch(self, epoch):
batch_size = len(next(iter(self.train_data))[0])
print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {batch_size} | Steps: {len(self.train_data)}")
for source, targets in self.train_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
self._run_batch(source, targets)
def _save_checkpoint(self, epoch):
checkpoint = self.model.state_dict()
PATH = "checkpoint.pt"
torch.save(checkpoint, PATH)
print(f"Epoch {epoch} | Training snapshot saved at {PATH}")
def train(self, max_epochs):
for epoch in range(max_epochs):
self._run_epoch(epoch)
if epoch % self.save_every == 0:
self._save_checkpoint(epoch)
def load_train_objs():
model = torch.nn.Sequential(
torch.nn.Linear(20, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 1)
)
train_data = DataLoader(CustomDataset(100), batch_size=10, shuffle=True)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
return model, train_data, optimizer
def main(save_every, total_epochs):
model, train_data, optimizer = load_train_objs()
trainer = Trainer(model, train_data, optimizer, 0, save_every)
trainer.train(total_epochs)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
device = 0 # shorthand for cuda:0
main(device, args.total_epochs, args.save_every, args.batch_size)
This code contains a Trainer class responsible for training, a CustomDataset class for data loading, and functions for initializing objects and running the training process.
Single-Machine DDP:
To implement DDP, the first step is initializing a distributed process group. This group comprises all processes running on our GPUs, typically one process per GPU. Setting up this group is essential for processes to discover and communicate with each other. We’ll create a function for this purpose.
from torch.distributed import init_process_group, destroy_process_group
def initialize_process_group(world_size, rank):
# Define environment variables
os.environ["MASTER_ADDR"] = "localhost" # change this to your master node's IP address: It is used for each process to communicate with each other
os.environ["MASTER_PORT"] = "12355" # change this to your master node's port: It is used for each process to find each other
init_process_group(backend="nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank) # set the device process
In this function, world_size represents the total number of processes in the group, and rank is a unique identifier for each process. We set environment variables such as master_addr, which refers to the IP address of the machine running the process with rank 0. For multi-node setups, this address would be the IP of the master node. master_port coordinates communication between processes.
We then call init_process_group with backend='nccl' to initialize the default distributed process group. This function ensures that processes can communicate using the specified backend (in this case, “nccl” for NVIDIA GPUs).
Next, we’ll modify the Trainer class to wrap the model with torch.nn.parallel.DistributedDataParallel. This ensures that the model is replicated across multiple GPUs and gradients are synchronized during training. Also, in the _save_checkpoint method, we need to access the module’s state dictionary when saving the model checkpoint. Here’s the updated Trainer class:
from torch.nn.parallel import DistributedDataParallel as DDP
class Trainer:
def __init__(self,
model: torch.nn.Module,
train_data: DataLoader,
optimizer,
rank: int,
save_every: int) -> None:
self.rank = rank
self.model = DDP(model.to(rank), device_ids=[rank])
self.train_data = train_data
self.optimizer = optimizer
self.save_every = save_every
def _save_checkpoint(self, epoch):
checkpoint = self.model.module.state_dict() # Access module's state_dict
PATH = f"checkpoint_rank{self.rank}.pt"
torch.save(checkpoint, PATH)
print(f"Epoch {epoch} | Training snapshot saved at {PATH}")
Furthermore, we need to adjust the data loading process to ensure that data is properly distributed across GPUs. We’ll use torch.utils.data.distributed.DistributedSampler and set shuffle=False. Here’s how to prepare the data loader:
def prepare_dataloader(dataset, batch_size):
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
return DataLoader(dataset, batch_size=batch_size, sampler=sampler)
Lastly, we’ll update the main function to include the initialization and destruction of the distributed process group:
def main(rank: int, world_size: int, save_every: int, total_epochs: int):
initialize_process_group(rank, world_size)
model, train_data, optimizer = load_train_objs()
train_data = prepare_dataloader(train_data, batch_size=10)
trainer = Trainer(model, train_data, optimizer, rank, save_every)
trainer.train(total_epochs)
destroy_process_group()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
world_size = torch.cuda.device_count()
# Using mp.spawn
mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
By making these changes, we ensure that our training code is compatible with DDP and can effectively utilize multiple GPUs for accelerated training.